:quality(85):upscale()/2025/11/10/782/n/49351757/8170ecd6691224df8bd1d7.49547606_.png)
:quality(85):upscale()/2025/11/21/894/n/24155406/f08298fe6920cb78a61ca3.64427622_.jpg)
:quality(85):upscale()/2025/10/31/699/n/24155406/907a28006904d9f5870b34.67078517_.png)
:quality(85):upscale()/2025/11/26/724/n/1922153/364868b6692729990f9002.05869709_.png)














Amazon unveils 192-core Graviton5 CPU with massive 180 MB L3 cache in tow — ambitious server silicon challenges high-end AMD EPYC and Intel Xeon in the cloud


This month, Amazon Web Services introduced the Graviton5, its fifth-generation custom general-purpose server processor, designed to compete against industry-standard CPUs from AMD and Intel in AWS's data centers. The new processor extends AWS's in-house Arm-based CPU program with a CPU that packs up to 192 cores and 180 MB of L3 cache, and is designed to compete with higher-end AMD EPYC and Intel Xeon processors, potentially replacing some of them in AWS data centers.
At a glance
The new processor is now available in Amazon EC2 M9g instances in preview, while compute-optimized C9g and memory-focused R9g variants are scheduled for launch in 2026. The current EC2 M9g instances are up to 30% faster for databases, up to 35% faster for web applications, and up to 35% faster for machine learning workloads compared to M8g, according to AWS.
Diving deeper: 192 Neoverse V3 cores
Amazon Web Services is intentionally opaque about the exact specifications and internal design of its Graviton5 CPU. Nonetheless, it offers comparisons with the previous-generation Graviton4 chip, which allows us to decode some details and delve into them with a little more depth.
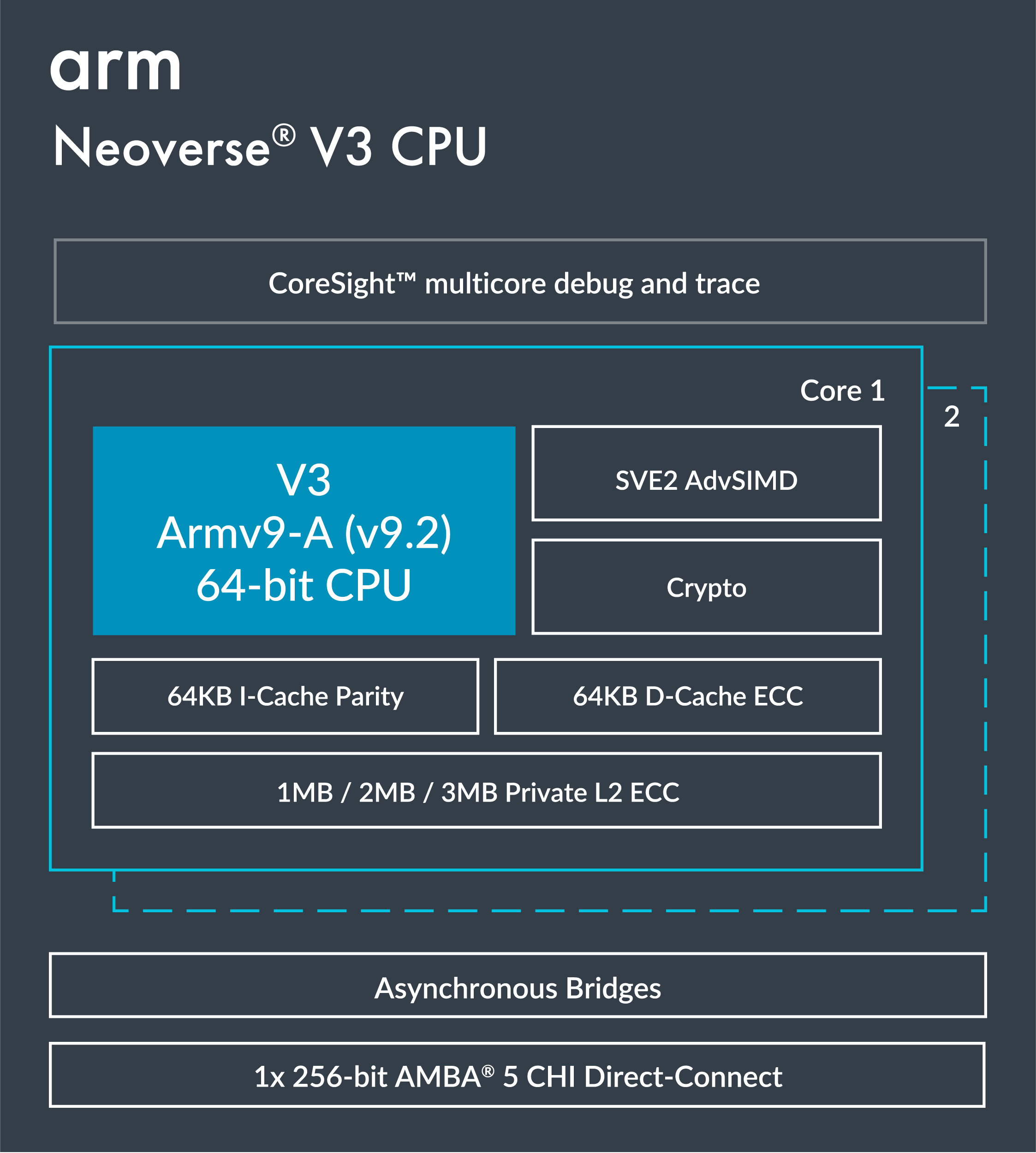
AWS and Arm officially confirm that Graviton5 integrates 192 Neoverse V3 cores per package, fabricated using a 3nm-class process, making it the densest CPU in the Graviton lineup and the densest Armv9.2 processor available to date. The internal layout of the processor has been redesigned to reduce communication overhead, and AWS claims up to 33% lower inter-core latency, which is particularly noteworthy given the twofold increase in core count.
When we discuss Neoverse V3, we cannot help but think about the Arm-developed compute subsystems (CSS). While Arm confirmed that we are dealing with Neoverse V3, neither Amazon nor Arm has confirmed that Graviton5 uses Arm-developed CSS. That means we're likely dealing with a unique design in Graviton 5.
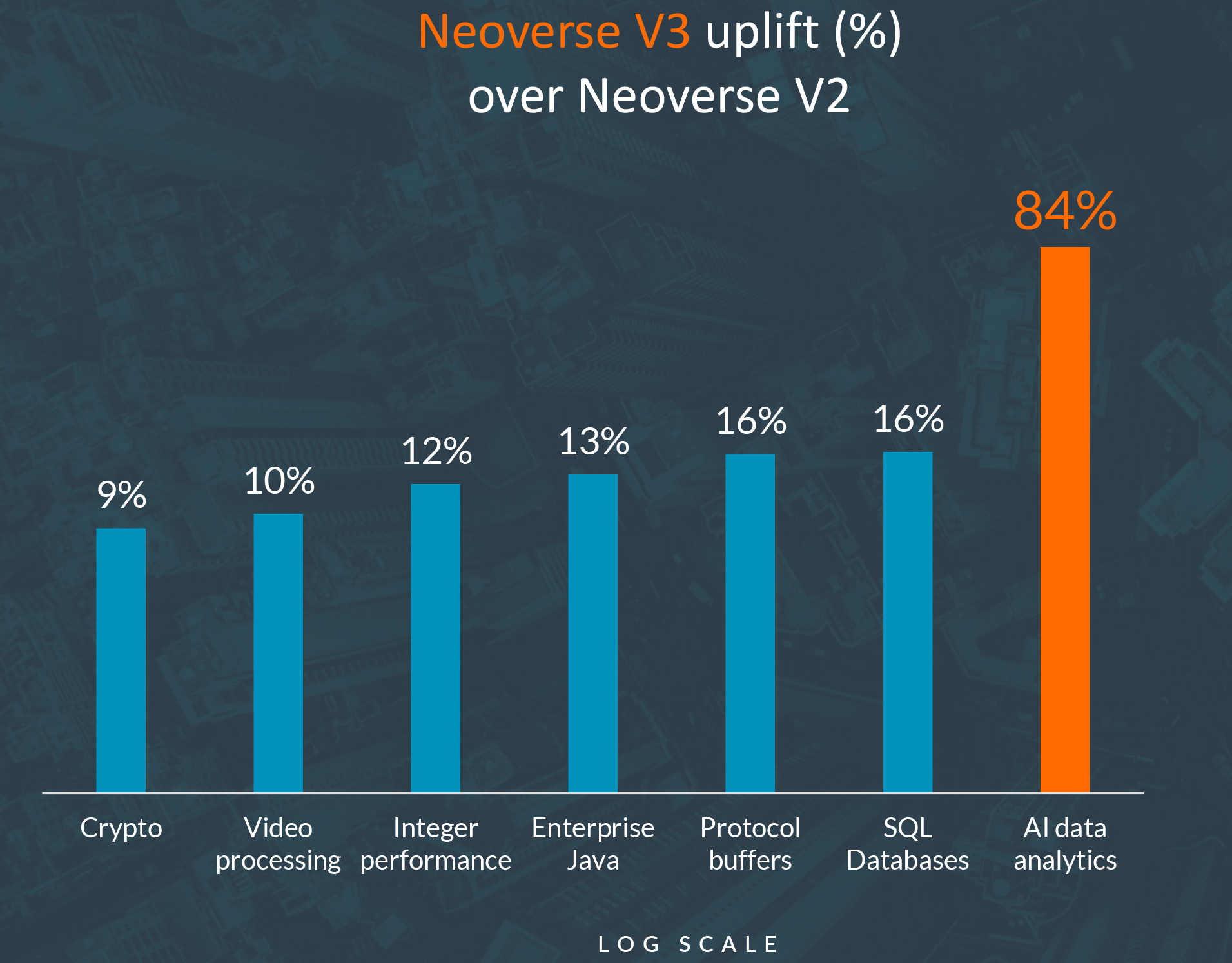
In performance comparisons between the Neoverse V3 core and its predecessor, Arm claims a 9%-16% uplift over Neoverse V2 across general cloud workloads and up to 84% in AI data analytics. This is one of the reasons why AWS is so conservative about performance upticks, both for Graviton5 as well as compute-intensive M9g instances in general. Another reason for AWS's conservative performance estimate is that it does not sell leading-edge performance like AMD or Nvidia, but rather predictable performance per dollar and scalability in the cloud. Nonetheless, with a 192-core processor, AWS puts itself into the highest league among CPU developers.
L3 cache replaces system-level cache
One interesting thing to note about Graviton5 is that it comes with L3 cache, not system-level cache like Graviton4. While L3 and SLC in data center CPUs have a lot in common, they are not the same thing. Traditionally, L3 cache is a last-level cache located inside each compute tile or core cluster in a data center CPU. L3 primarily serves CPU workloads by reducing DRAM access; it is optimized for low latency and directly participates in the core's coherence protocol. Therefore, L3 is tightly coupled to the cores and is physically close to them.

By contrast, SLC sits outside the core clusters on the SoC fabric and is shared by all CPU cores, various other accelerators, I/O devices, NICs, and DMA engines. It tends to be much larger (often 100–300+ MB) and optimized for throughput rather than latency, as it acts as a global buffer that reduces pressure on DRAM and provides coherent access for heterogeneous compute blocks. SLC can improve scaling for very high core counts and enables unified memory semantics across CPUs, GPUs, and on-die accelerators, a role traditional L3 caches cannot fulfill on their own.
Amazon has not publicly explained the design decision, but based on Graviton4’s architecture and what we know about Graviton5, the reason is almost certainly architectural scalability. The move from SLC in Graviton4 to a large 180 MB L3 in Graviton5 is not cosmetic; it reflects fundamental changes in how a 192-core processor moves data, manages latency, and maintains coherence.
Graviton4's architecture — 96 Neoverse V2 cores, a CMN-700 mesh, 12 DDR5-5600 channels — operates efficiently with a centralized or semi-centralized SLC. But doubling the core count to 192 dramatically increases mesh traffic, hop distances, and contention on any unified cache structure. At this scale, a monolithic SLC could almost certainly become a latency bottleneck and would not support AWS’s claim of up to 33% lower inter-core communication latency. A distributed L3 sliced across the die allows hot data to remain physically close to compute clusters, reducing average access latency and improving overall coherence behavior.
The fivefold cache expansion AWS advertises reinforces this architectural necessity. Scaling Graviton4's 36 MB SLC by that factor yields 180 MB, and AWS's additional statement —2.6X more cache per core, at double the core count — implies ~187 MB total, which aligns with a large, multi-slice L3 rather than a single SLC block, which would create routing complexity.
Finally, L3-based designs offer stronger multi-tenant performance predictability, which is crucial for AWS. Under cloud workloads, shared caches experience heavy cross-tenant interference and variable latency, so when designing cache subsystems, developers must take into account AWS's use case. To sum things up, the shift to a distributed L3 was a necessary architectural evolution for Graviton5.
New memory subsystem, I/O, and security features
Just as AWS didn't disclose many details about other design aspects of Graviton5, it also didn't disclose much about the memory subsystem of the CPU. It goes without saying that Graviton5's memory subsystem is more powerful than that of Graviton4, as it supports higher memory speeds, which likely means that it at least retains a 12-channel memory subsystem of the Graviton4, but with higher data transfer rates (i.e., higher than DDR5-5600).
A 12-channel DDR5 design operating at 6400 MT/s would provide around 614 GB/s of aggregate bandwidth, which translates to approximately 3.2 GB/s per core, which is actually lower than 5.6 GB/s per core in the case of Graviton4. However, the larger L3 cache could compensate for this decrease in memory bandwidth. Then again, we do not know the exact number of memory channels supported by Graviton5.
Input/output throughput is similarly increased, according to AWS: network bandwidth is up by 15% on average across instance sizes, with as much as double the throughput for the largest configurations. Storage bandwidth through Amazon EBS rises by around 20% on average, according to AWS. These gains are designed to improve performance not only for compute-heavy applications, but also for distributed systems that depend on fast storage and networking.
On the security side, Graviton5 is built on the AWS Nitro System, with sixth-generation Nitro Cards that handle virtualization, networking, and storage. AWS has also introduced a new component called the Nitro Isolation Engine, which the company describes as a formally verified isolation layer. Instead of relying solely on conventional security validation, the Isolation Engine uses mathematical proofs to demonstrate that workloads are separated from each other and from AWS operators. The architecture enforces a zero-operator-access model, and AWS plans to allow customers to review the implementation and the formal proofs behind it to ensure maximum security. Such security measures could be a part of the company's effort to attract clients who have traditionally used on-prem servers.
Wrapping it up
AWS's new Graviton5 processor offers a 192-core, 3nm Arm-based CPU with around 180 MB of L3 cache. This positions the cloud giant as a competitor to the high-end AMD EPYC and Intel Xeon solutions for data centers. The CPU integrates Neoverse V3 cores and delivers an advertised 25% performance uplift, which is conservative given the twofold increase in core count, large microarchitectural improvements in the Armv9.2 ISA, and a fivefold increase in cache capacity. Also, AWS confirms 33% lower inter-core latency due to a redesigned internal layout but has not disclosed whether it uses Arm's CSS, suggesting that Graviton5 may be a unique Annapurna Labs design built around Neoverse V3 cores.
A key architectural shift is replacing Graviton4's SLC with a large distributed L3 to enable better coherence scaling across 192 cores and predictable latency. The processor also gains a faster memory subsystem (likely retaining 12 channels at higher DDR5 speeds), improved network and storage bandwidth, and the new Nitro Isolation Engine, which uses formal verification to guarantee tenant isolation and enforce zero-operator access.
At present, Graviton5 powers new EC2 M9g instances — up to 30% – 35% faster for databases, web services, and machine learning — and compute-optimized C9g and memory-optimized R9g variants will follow in 2026.
Anton Shilov is a contributing writer at Tom’s Hardware. Over the past couple of decades, he has covered everything from CPUs and GPUs to supercomputers and from modern process technologies and latest fab tools to high-tech industry trends.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0